bundles / scipy latest / scipy / stats / _qmc / PoissonDisk
ABCMeta
scipy.stats._qmc:PoissonDisk
source: /scipy/stats/_qmc.py :1960
Signature
def PoissonDisk ( d : int | numpy.integer , * , radius : float | numpy.floating | numpy.integer = 0.05 , hypersphere : Literal['volume', 'surface'] = volume , ncandidates : int | numpy.integer = 30 , optimization : Literal['random-cd', 'lloyd'] | None = None , rng : int | numpy.integer | numpy.random._generator.Generator | numpy.random.mtrand.RandomState | None = None , l_bounds : npt.ArrayLike | None = None , u_bounds : npt.ArrayLike | None = None , seed = None ) → None Members
-
__init__ -
_hypersphere_surface_sample -
_hypersphere_volume_sample -
_initialize_grid_pool -
_random -
fill_space -
reset
Summary
Poisson disk sampling.
Parameters
d: intDimension of the parameter space.
radius: floatMinimal distance to keep between points when sampling new candidates.
hypersphere: {"volume", "surface"}, optionalSampling strategy to generate potential candidates to be added in the final sample. Default is "volume".
volume: original Bridson algorithm as described in [1]. New candidates are sampled within the hypersphere.surface: only sample the surface of the hypersphere.
ncandidates: intNumber of candidates to sample per iteration. More candidates result in a denser sampling as more candidates can be accepted per iteration.
optimization: {None, "random-cd", "lloyd"}, optionalWhether to use an optimization scheme to improve the quality after sampling. Note that this is a post-processing step that does not guarantee that all properties of the sample will be conserved. Default is None.
random-cd: random permutations of coordinates to lower the centered discrepancy. The best sample based on the centered discrepancy is constantly updated. Centered discrepancy-based sampling shows better space-filling robustness toward 2D and 3D subprojections compared to using other discrepancy measures.lloyd: Perturb samples using a modified Lloyd-Max algorithm. The process converges to equally spaced samples.
rng: `numpy.random.Generator`, optionalPseudorandom number generator state. When
rngis None, a new numpy.random.Generator is created using entropy from the operating system. Types other than numpy.random.Generator are passed to numpy.random.default_rng to instantiate aGenerator.l_bounds, u_bounds: array_like (d,)Lower and upper bounds of target sample data.
Notes
Poisson disk sampling is an iterative sampling strategy. Starting from a seed sample, ncandidates are sampled in the hypersphere surrounding the seed. Candidates below a certain radius or outside the domain are rejected. New samples are added in a pool of sample seed. The process stops when the pool is empty or when the number of required samples is reached.
The maximum number of point that a sample can contain is directly linked to the radius. As the dimension of the space increases, a higher radius spreads the points further and help overcome the curse of dimensionality. See the quasi monte carlo tutorial <quasi-monte-carlo> for more details.
Some code taken from [2], written consent given on 31.03.2021 by the original author, Shamis, for free use in SciPy under the 3-clause BSD.
Examples
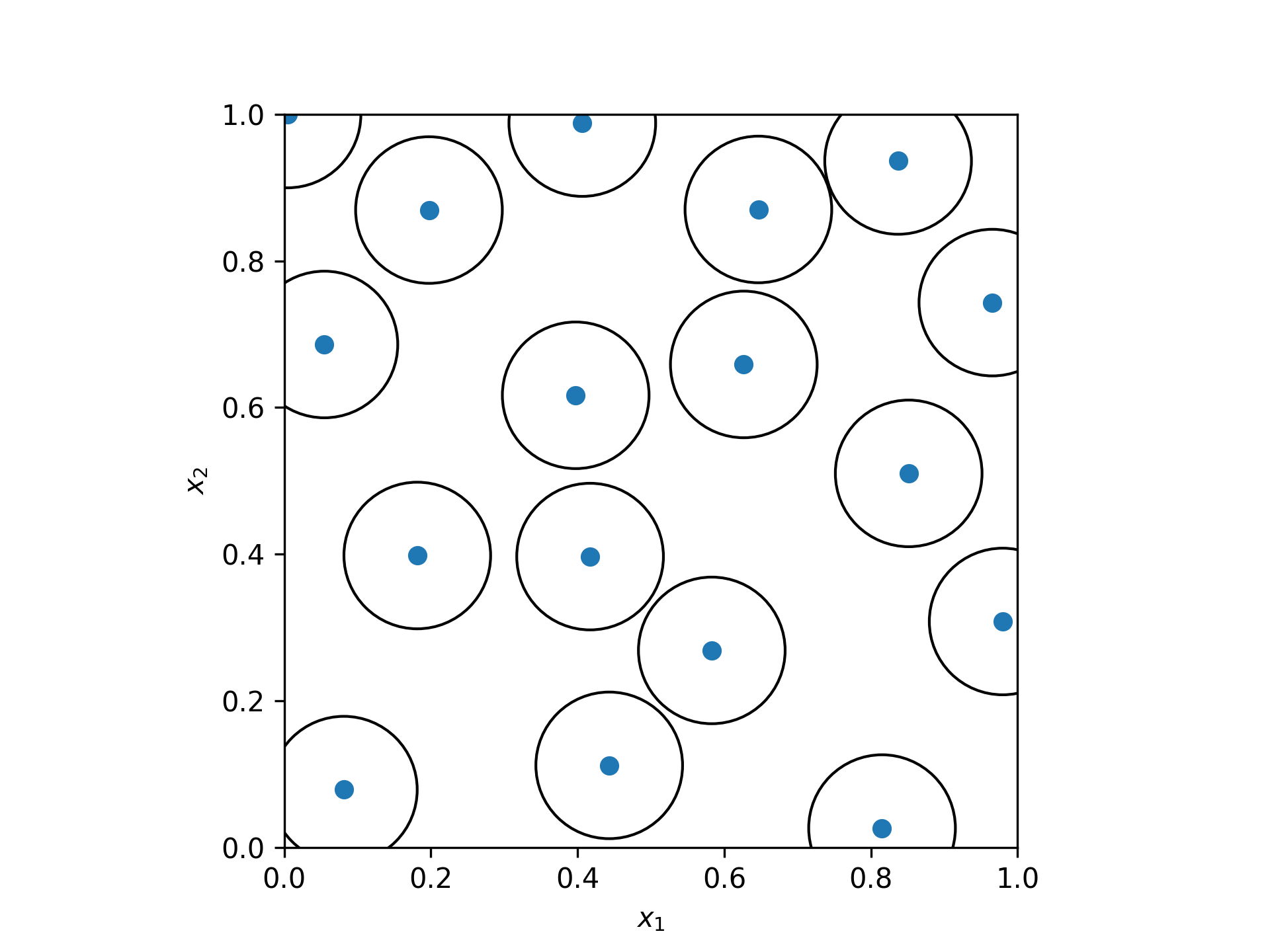
Generate a 2D sample using a `radius` of 0.2.import numpy as np import matplotlib.pyplot as plt from matplotlib.collections import PatchCollection from scipy.stats import qmc rng = np.random.default_rng() radius = 0.2 engine = qmc.PoissonDisk(d=2, radius=radius, rng=rng) sample = engine.random(20)✓
fig, ax = plt.subplots() _ = ax.scatter(sample[:, 0], sample[:, 1]) circles = [plt.Circle((xi, yi), radius=radius/2, fill=False) for xi, yi in sample] collection = PatchCollection(circles, match_original=True)✓
ax.add_collection(collection)
✗_ = ax.set(aspect='equal', xlabel=r'$x_1$', ylabel=r'$x_2$', xlim=[0, 1], ylim=[0, 1]) plt.show()✓
Aliases
-
scipy.stats._qmc.PoissonDisk