bundles / scipy latest / scipy / stats / _fit / goodness_of_fit
function
scipy.stats._fit:goodness_of_fit
source: /scipy/stats/_fit.py :743
Signature
def goodness_of_fit ( dist , data , * , known_params = None , fit_params = None , guessed_params = None , statistic = ad , n_mc_samples = 9999 , rng = None , random_state = None ) Summary
Perform a goodness of fit test comparing data to a distribution family.
Extended Summary
Given a distribution family and data, perform a test of the null hypothesis that the data were drawn from a distribution in that family. Any known parameters of the distribution may be specified. Remaining parameters of the distribution will be fit to the data, and the p-value of the test is computed accordingly. Several statistics for comparing the distribution to data are available.
Parameters
dist: `scipy.stats.rv_continuous`The object representing the distribution family under the null hypothesis.
data: 1D array_likeFinite, uncensored data to be tested.
known_params: dict, optionalA dictionary containing name-value pairs of known distribution parameters. Monte Carlo samples are randomly drawn from the null-hypothesized distribution with these values of the parameters. Before the statistic is evaluated for the observed
dataand each Monte Carlo sample, only remaining unknown parameters of the null-hypothesized distribution family are fit to the samples; the known parameters are held fixed. If all parameters of the distribution family are known, then the step of fitting the distribution family to each sample is omitted.fit_params: dict, optionalA dictionary containing name-value pairs of distribution parameters that have already been fit to the data, e.g. using scipy.stats.fit or the
fitmethod ofdist. Monte Carlo samples are drawn from the null-hypothesized distribution with these specified values of the parameter. However, these and all other unknown parameters of the null-hypothesized distribution family are always fit to the sample, whether that is the observeddataor a Monte Carlo sample, before the statistic is evaluated.guessed_params: dict, optionalA dictionary containing name-value pairs of distribution parameters which have been guessed. These parameters are always considered as free parameters and are fit both to the provided
dataas well as to the Monte Carlo samples drawn from the null-hypothesized distribution. The purpose of theseguessed_paramsis to be used as initial values for the numerical fitting procedure.statistic: {"ad", "ks", "cvm", "filliben"} or callable, optionalThe statistic used to compare data to a distribution after fitting unknown parameters of the distribution family to the data. The Anderson-Darling ("ad") [1], Kolmogorov-Smirnov ("ks") [1], Cramer-von Mises ("cvm") [1], and Filliben ("filliben") [7] statistics are available. Alternatively, a callable with signature
(dist, data, axis)may be supplied to compute the statistic. Heredistis a frozen distribution object (potentially with array parameters),datais an array of Monte Carlo samples (of compatible shape), andaxisis the axis ofdataalong which the statistic must be computed.n_mc_samples: int, default: 9999The number of Monte Carlo samples drawn from the null hypothesized distribution to form the null distribution of the statistic. The sample size of each is the same as the given
data.rng: {None, int, `numpy.random.Generator`}, optionalIf
rngis passed by keyword, types other than numpy.random.Generator are passed to numpy.random.default_rng to instantiate aGenerator. Ifrngis already aGeneratorinstance, then the provided instance is used. Specifyrngfor repeatable function behavior.If this argument is passed by position or
random_stateis passed by keyword, legacy behavior for the argumentrandom_stateapplies:If
random_stateis None (or numpy.random), the numpy.random.RandomState singleton is used.If
random_stateis an int, a newRandomStateinstance is used, seeded withrandom_state.If
random_stateis already aGeneratororRandomStateinstance then that instance is used.
Returns
res: GoodnessOfFitResultAn object with the following attributes.
fit_result
fit_result
statistic
statistic
pvalue
pvalue
null_distribution
null_distribution
Notes
This is a generalized Monte Carlo goodness-of-fit procedure, special cases of which correspond with various Anderson-Darling tests, Lilliefors' test, etc. The test is described in [2], [3], and [4] as a parametric bootstrap test. This is a Monte Carlo test in which parameters that specify the distribution from which samples are drawn have been estimated from the data. We describe the test using "Monte Carlo" rather than "parametric bootstrap" throughout to avoid confusion with the more familiar nonparametric bootstrap, and describe how the test is performed below.
Traditional goodness of fit tests
Traditionally, critical values corresponding with a fixed set of significance levels are pre-calculated using Monte Carlo methods. Users perform the test by calculating the value of the test statistic only for their observed data and comparing this value to tabulated critical values. This practice is not very flexible, as tables are not available for all distributions and combinations of known and unknown parameter values. Also, results can be inaccurate when critical values are interpolated from limited tabulated data to correspond with the user's sample size and fitted parameter values. To overcome these shortcomings, this function allows the user to perform the Monte Carlo trials adapted to their particular data.
Algorithmic overview
In brief, this routine executes the following steps:
Fit unknown parameters to the given
data, thereby forming the "null-hypothesized" distribution, and compute the statistic of this pair of data and distribution.Draw random samples from this null-hypothesized distribution.
Fit the unknown parameters to each random sample.
Calculate the statistic between each sample and the distribution that has been fit to the sample.
Compare the value of the statistic corresponding with
datafrom (1) against the values of the statistic corresponding with the random samples from (4). The p-value is the proportion of samples with a statistic value greater than or equal to the statistic of the observed data.
In more detail, the steps are as follows.
First, any unknown parameters of the distribution family specified by dist are fit to the provided data using maximum likelihood estimation. (One exception is the normal distribution with unknown location and scale: we use the bias-corrected standard deviation np.std(data, ddof=1) for the scale as recommended in [1].) These values of the parameters specify a particular member of the distribution family referred to as the "null-hypothesized distribution", that is, the distribution from which the data were sampled under the null hypothesis. The statistic, which compares data to a distribution, is computed between data and the null-hypothesized distribution.
Next, many (specifically n_mc_samples) new samples, each containing the same number of observations as data, are drawn from the null-hypothesized distribution. All unknown parameters of the distribution family dist are fit to each resample, and the statistic is computed between each sample and its corresponding fitted distribution. These values of the statistic form the Monte Carlo null distribution (not to be confused with the "null-hypothesized distribution" above).
The p-value of the test is the proportion of statistic values in the Monte Carlo null distribution that are at least as extreme as the statistic value of the provided data. More precisely, the p-value is given by
where is the number of statistic values in the Monte Carlo null distribution that are greater than or equal to the statistic value calculated for data, and is the number of elements in the Monte Carlo null distribution (n_mc_samples). The addition of to the numerator and denominator can be thought of as including the value of the statistic corresponding with data in the null distribution, but a more formal explanation is given in [5].
Limitations
The test can be very slow for some distribution families because unknown parameters of the distribution family must be fit to each of the Monte Carlo samples, and for most distributions in SciPy, distribution fitting performed via numerical optimization.
Anti-Pattern
For this reason, it may be tempting to treat parameters of the distribution pre-fit to data (by the user) as though they were known_params, as specification of all parameters of the distribution precludes the need to fit the distribution to each Monte Carlo sample. (This is essentially how the original Kilmogorov-Smirnov test is performed.) Although such a test can provide evidence against the null hypothesis, the test is conservative in the sense that small p-values will tend to (greatly) overestimate the probability of making a type I error (that is, rejecting the null hypothesis although it is true), and the power of the test is low (that is, it is less likely to reject the null hypothesis even when the null hypothesis is false). This is because the Monte Carlo samples are less likely to agree with the null-hypothesized distribution as well as data. This tends to increase the values of the statistic recorded in the null distribution, so that a larger number of them exceed the value of statistic for data, thereby inflating the p-value.
Array API Standard Support
goodness_of_fit is not in-scope for support of Python Array API Standard compatible backends other than NumPy.
See dev-arrayapi for more information.
Examples
A well-known test of the null hypothesis that data were drawn from a given distribution is the Kolmogorov-Smirnov (KS) test, available in SciPy as `scipy.stats.ks_1samp`. Suppose we wish to test whether the following data:import numpy as np from scipy import stats rng = np.random.default_rng(1638083107694713882823079058616272161) x = stats.uniform.rvs(size=75, random_state=rng)✓
loc, scale = np.mean(x), np.std(x, ddof=1) cdf = stats.norm(loc, scale).cdf✓
stats.ks_1samp(x, cdf)
✗known_params = {'loc': loc, 'scale': scale} res = stats.goodness_of_fit(stats.norm, x, known_params=known_params, statistic='ks', rng=rng)✓
res.statistic, res.pvalue
✗res = stats.goodness_of_fit(stats.norm, x, statistic='ks', rng=rng)
✓res.statistic, res.pvalue
✗res = stats.anderson(x, 'norm', method='interpolate') print(res.statistic) print(res.pvalue)✓
res = stats.goodness_of_fit(stats.norm, x, statistic='ad', rng=rng)
✓res.statistic, res.pvalue
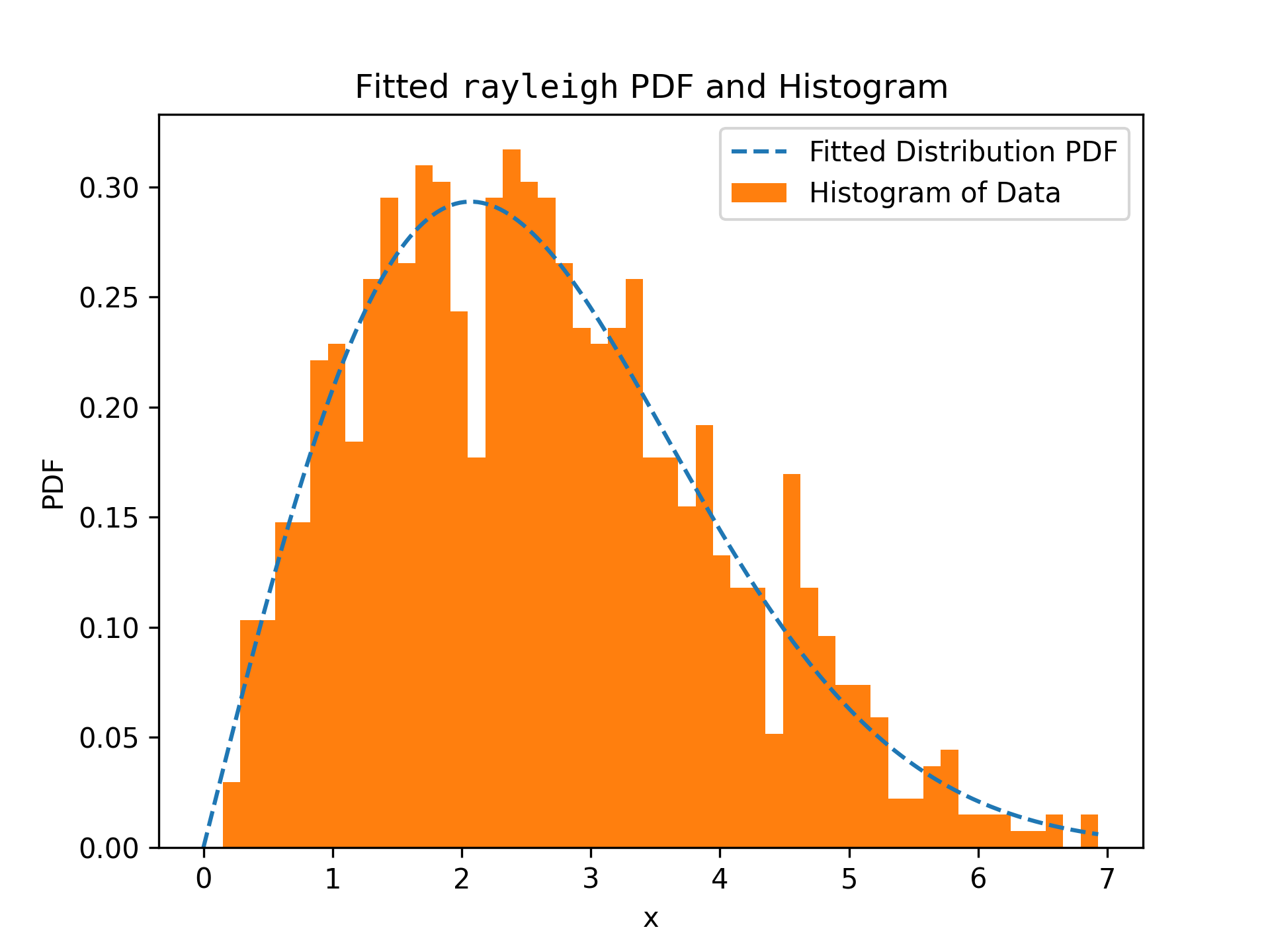
✗rng = np.random.default_rng() x = stats.chi(df=2.2, loc=0, scale=2).rvs(size=1000, random_state=rng) res = stats.goodness_of_fit(stats.rayleigh, x, statistic='cvm', known_params={'loc': 0}, rng=rng)✓
res.fit_result # location is as specified, and scale is reasonable
✗import matplotlib.pyplot as plt # matplotlib must be installed to plot
✓res.fit_result.plot()
✗plt.show()
✓
_, ax = plt.subplots()
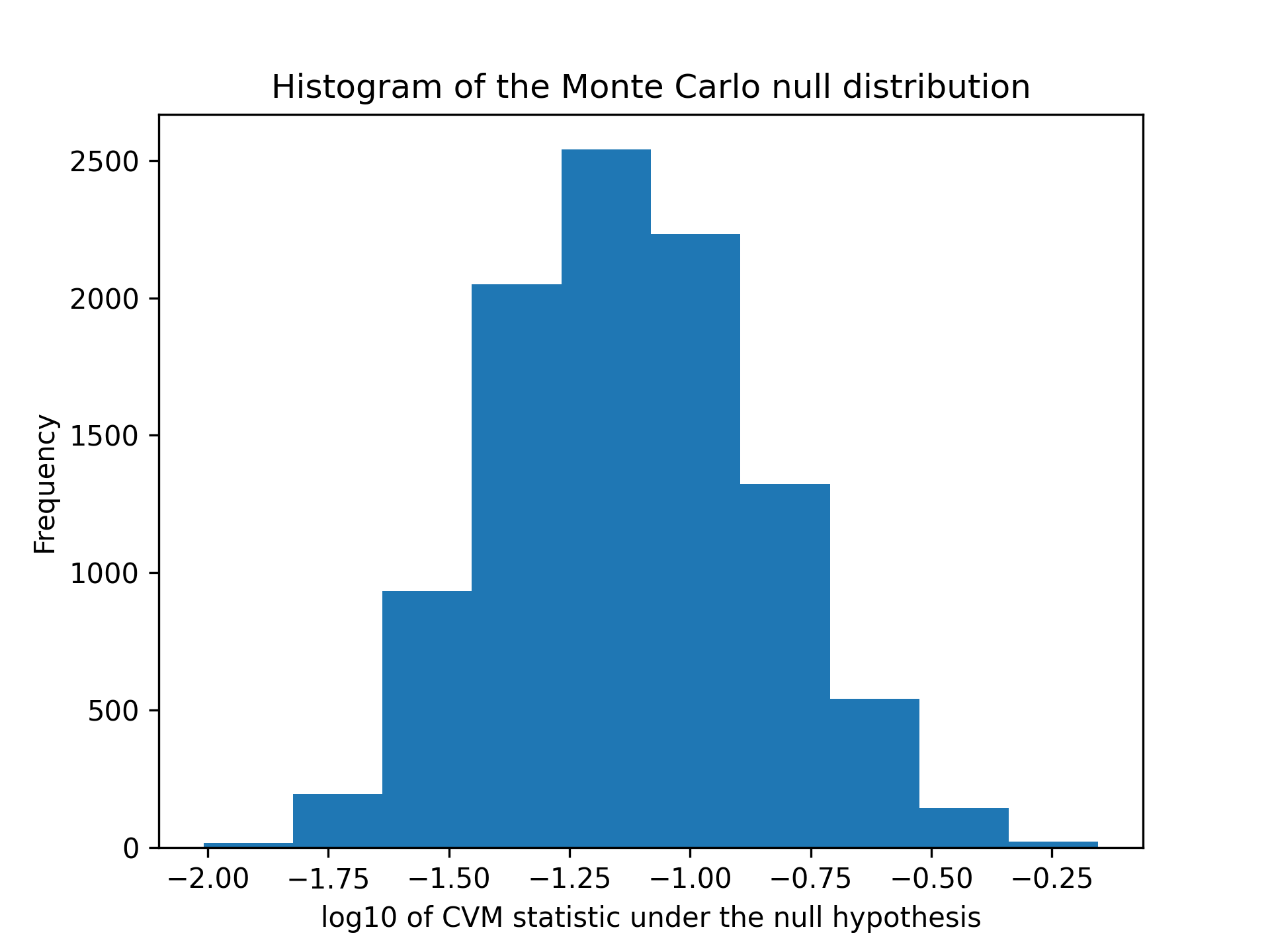
✓ax.hist(np.log10(res.null_distribution)) ax.set_xlabel("log10 of CVM statistic under the null hypothesis") ax.set_ylabel("Frequency") ax.set_title("Histogram of the Monte Carlo null distribution")✗
plt.show()
✓
res.statistic, res.pvalue
✗Aliases
-
scipy.stats.goodness_of_fit